هوش مصنوعی در «نشان»؛ جهش ۹۰ درصدی اتوماسیون و مدیریت هوشمند نظرات کاربران
«نقشه و مسیریاب نشان» با بهرهگیری از معماریهای پیشرفته پردازش زبان طبیعی و مدلهای زبانی بزرگ، فرایند بررسی و مدیریت نظرات کاربران را تا ۹۰ درصد اتومات کرده است. این سامانه با حفظ دقت ۹۹٫۹۹ درصدی در تشخیص، انتشار یا رد کامنتها را از چندین روز به کمتر از یک روز کاهش داده و تجربه کاربری را به شکل چشمگیری بهبود بخشیده است.
به گزارش توسعه برند، این محتوا ارزش فوقالعادهای دارد، چون میتواند به سایر کاربران کمک کند تا در مورد انتخاب یک مکان بهتر تصمیم بگیرند. اما سوال مهم این است: آیا تمام این کامنتها قابل انتشار هستند؟
پاسخ کوتاه: خیر.
چه کامنتهایی منتشر نمیشوند؟
آنچه میخوانید:
ما برای حفظ کیفیت محتوا و تجربهی کاربری بهتر، یک سری از نظرات را منتشر نمیکنیم. موارد زیر برخی از مهمترین دلایل منتشر نشدن این کامنتها هستند:
۱. کامنت غیرمرتبط
کامنتی که برای یک مکان گذاشته شده اما اطلاعات مکان دیگری را میدهد، غیرمرتبط است. بهطور مثال تصور کنید که کاربری به یک مرکز خرید مراجعه و از یکی از فروشگاههای آنجا خرید کرده است. حالا کاربر ممکن است کامنتی را به اشتباه برای یک فروشگاه دیگر و یا بر روی خود مرکز خرید بگذارد. از آنجا که این کامنت ارتباطی با آن مکان ندارد، آن را منتشر نمیکنیم و به کاربر اطلاع میدهیم که کامنتی که گذاشته مرتبط با آن مکان نیست و باید نظرش را روی مکان درست بنویسد.
۲. کامنت غیرمفید
این کامنت، همانطور که از اسمش پیداست، به کاربران اطلاعات مفیدی درباره مکان مورد نظر نمیدهد؛ یعنی کمکی به تصمیمگیری کاربران دیگر برای رفتن یا نرفتن به آن مکان نمیکند. بهعنوان مثال تصور کنید که کاربری بر روی یک رستوران کامنت گذاشته: «دیوارهاش سفیده». این کامنت اطلاعات مفیدی ندارد و به کاربران کمکی در انتخاب مکان نمیکند. پس بهتر است به کاربر بازخورد دهیم تا سعی کند کامنت مفیدتری برای انتشار ارسال کند.
۳. کامنت نقضکننده حریم خصوصی
کامنتهایی که حاوی اطلاعاتی درباره شخص یا اشخاصی است به طوری که نمیتوانیم بدانیم شخص مورد نظر مشکلی با انتشار این کامنت روی نقشه دارد یا خیر. در این صورت از انتشار این نوع کامنت ها روی نقشه جلوگیری میکنیم.
۴. کامنت توهینآمیز یا آزاردهنده
گاهی ممکن است کاربران تجربهشان از یک مکان را در کامنتی بسیار تند یا توهینآمیز ارسال کنند. این کامنتها که محتوایی آزاردهنده دارند، در نشان منتشر نمیشوند.
۵. کامنت اسپم
به کامنتهایی که محتوای تبلیغاتی یا تکراری دارند، کامنت اسپم میگوییم و از انتشار آنها جلوگیری میکنیم.
پیش از هوش مصنوعی: همهچیز با نظارت انسانی
تا پیش از اتومات شدن این فرایند، تمام کامنتها با نظارت نیروی انسانی بررسی میشدند. این روش با وجود دقت بالا، با یکسری چالش مواجه بود:
-
زمانبر بودن:بررسی هزاران کامنت بهصورت روزانه، کاری بسیار زمانبر و خستهکننده بود.
-
هزینهی بالا: سازمان برای جذب و آموزش ناظران جدید، هزینههای زیادی میپرداخت.
-
دشواری در اعمال سریع تغییرات: با تغییراتی در فرایند یا سیاستهای انتشار کامنتها، امکان اعمال سریع تغییرات وجود نداشت.
-
تأخیر در نمایش کامنتهای مفید:امکان انتشار سریع کامنتهایی که اطلاعات خوبی برای کاربران داشت و کمککننده بود، وجود نداشت.
چرا اتومیشن ضروری شد؟
با توجه به مشکلاتی که به آن اشاره کردیم و همچنین رشد سریع تعداد کاربران و نظرات، نیاز به سیستمی که بتواند سریع، دقیق و در مقیاس بزرگ تصمیمگیری کند، بیشتر از همیشه احساس شد. به همین دلیل تصمیم گرفتیم فرایند تأیید و رد کامنتها را با استفاده از پردازش متن فارسی و روشهای نوین یادگیری ماشین اتومیشن کنیم.
در مسیر اتومیشن با چه چالشهایی روبهرو شدیم؟
در حوزهی مدیریت محتوای کاربر، حتی یک تصمیم اشتباه میتواند پیامدهای جدی به دنبال داشته باشد:
-
حذف نادرست یک کامنت مفید ← کاهش رضایت کاربر و محروم کردن سایر کاربران از محتوایی که میتواند برای آنها مفید باشد.
-
انتشار یک کامنت نامناسب ← آسیب به تجربهی جمعی کاربران
پس سیستمی قابلقبول است که بتواند تصمیمهایی با اطمینان بسیار بالا بگیرد یا به عبارتی precision بالایی داشته باشد.
طراحی سیستم هوشمند بررسی کامنتها
برای توسعهی این سیستم، از معماریهای پیشرفتهی پردازش زبان طبیعی مبتنی بر Transformer با مکانیزم Self-Attention استفاده شد. این معماری با استفاده از یک مجموعه دادهی برچسبخورده از کامنتهای واقعی کاربران، Fine-tune شد تا بتواند در فضای مسئلهی «تأیید یا رد کامنت» عملکرد بهینهای داشته باشد.
پس از مرحلهی مدلسازی اولیه، یک ماژول post-process تفسیرپذیر توسعه دادیم تا بتواند خروجی مدل را با استفاده از تحلیل آماری n-gram و الگوهای معنایی استخراجشده ارزیابی کند. در این مرحله، وزندهی به توالیهای کلمات بر اساس احتمال وقوع آنها در دستههای مختلف انجام شده و نتایج با مجموعهای از قواعد تطبیق داده میشود.
با استفاده از این ترکیب، سیستم میتواند با قطعیت بالایی تشخیص دهد که یک کامنت به هیچیک از دستههای «غیرمرتبط»، «توهینآمیز»، «ناقض حریم خصوصی» و… تعلق ندارد.
مزیت این طراحی، ایجاد شفافیت در تصمیمگیری است: هر پیشبینی نهتنها بر اساس شبکهی عصبی ترانسفورمری انجام میشود، بلکه ماژول پسپردازش ما را از پیشبینی مدل مطمئن میکند. این رویکرد، با تضمین ۹۹٫۹۹٪ Precision، باعث میشود که تنها کامنتهایی بهصورت خودکار منتشر شوند که مدل و لایهی پسپردازش تفسیرپذیر، هر دو بر قابلانتشار بودن آنها توافق کامل داشته باشند.
افزایش نرخ اتومیشن با مدلهای زبانی بزرگ
در مرحلهی بعدی توسعه، برای پوشش کامنتهایی که مدل اولیه دربارهی آنها اطمینان کافی نداشت، از مدلهای زبانی بزرگ (LLM) بهره گرفتیم. این کار با استفاده از API مدلهای پیشرفتهی OpenAI و در قالب یک Pipeline ترکیبی انجام شد تا هم دقت بالایی داشته باشد و هم هزینهی پردازش را بهینه نگه دارد.
در این ساختار، ابتدا معماری ترنسفورمری ما پیشبینی اولیه را انجام میدهد. خروجیهایی که ماژول Post-Process آنها را «مطمئن» تشخیص بدهد، مستقیماً تعیین تکلیف میشوند. اما در مواردی که سطح اطمینان پایینتر از آستانهی تعریفشده باشد، کامنت به مرحلهی تحلیل توسط LLM ارسال میشود.
در این مرحله، با استفاده از تکنیکهای پیشرفتهی مهندسی پرامپت (Prompt Engineering)، متن ورودی، بازنویسی و ساختاردهی میشود تا مدل زبانی بتواند با حداقل تعداد توکن و با هزینهای بهصرفه، ارزیابی معنایی عمیقتری انجام دهد.
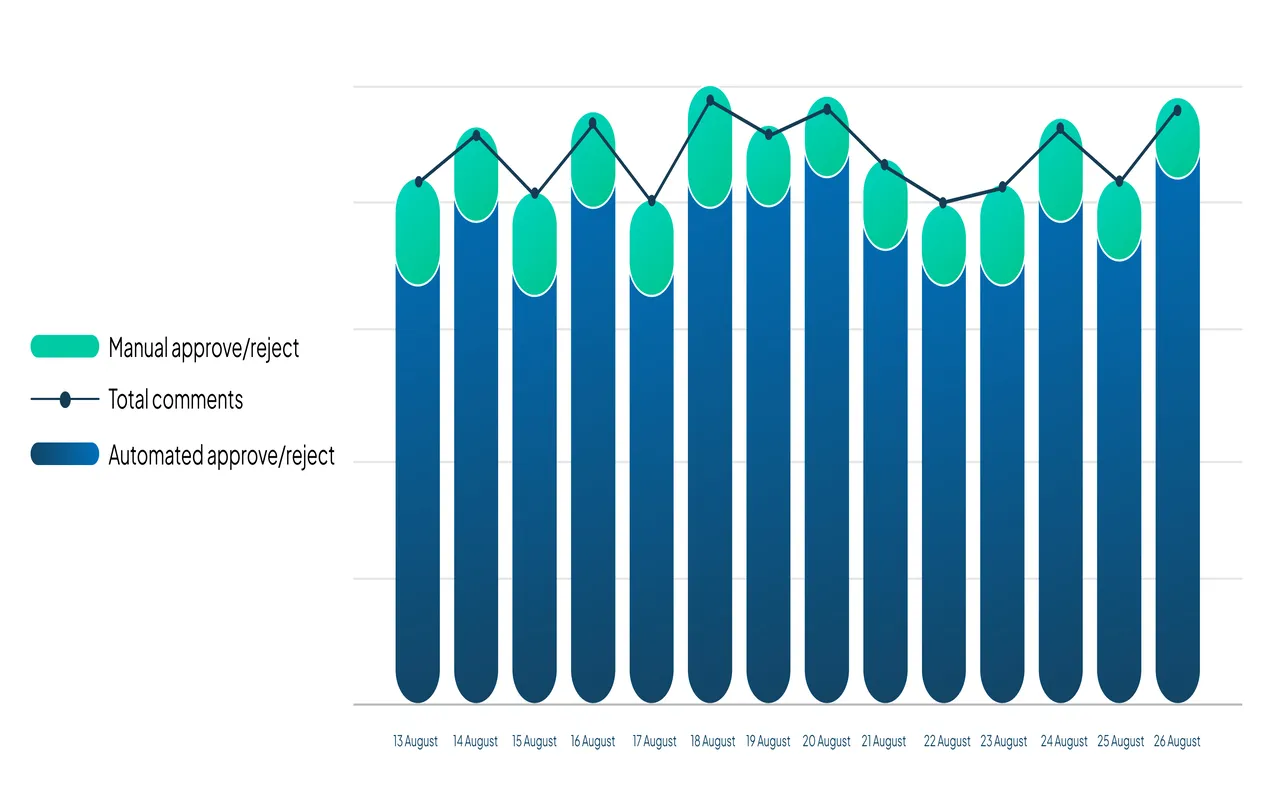
نتیجهی این رویکرد، بدون کوچکترین افت در Precision سیستم، افزایش نرخ اتومیشن از ۵۵٪ به ۹۰٪ بوده است. ترکیب سرعت و تفسیرپذیری مدلهای سبک با توانایی درک زمینهای و ظرافتهای زبانی LLM، تعادلی ایجاد کرده که از نظر هزینه، کیفیت و مقیاسپذیری ایدهآل است.
دستاوردها در یک نگاه
-
۹۰ درصد کامنتها اکنون بهصورت اتومات بررسی و تعیین تکلیف میشوند.
-
Precision سیستم در این دستهبندیها: ۹۹٫۹۹ درصد.
( یعنی از هر ۱۰٬۰۰۰ تصمیم، تنها یک مورد آن احتمالا خطا باشد.)
-
۱۰ درصد کامنتها که مدل دربارهی آنها اطمینان کافی ندارد، همچنان به تیم نظارت انسانی سپرده میشود.
-
کاهش بیش از ۹۰ درصدی زمان متوسط تأیید یا رد هر کامنت.
-
کاهش صدها ساعت زمان برای تیم نظارت انسانی
-
دیگر هیچ کامنتی بیشتر از یک روز منتظر تعیین تکلیف شدن نمیماند.
-
تسهیل فرایند تغییر در سیاستهای رد یا تایید کامنتها؛ بهطوریکه بعد از داشتن سرویس هوشمند تعیین تکلیف کامنتها، توانستیم بهراحتی یک دلیل رد جدید با عنوان «اسپم» اضافه کنیم، بدون این که نیاز باشد زمان یا هزینهای برای آموزش نیروهای نظارت انسانی صرف کنیم.
منبع: نشان

